



Automatic Classification is a new advanced artificial intelligence feature developed by Lexum for the CanLII website. The Automatic Classification feature leverages artificial intelligence algorithms and natural language processing techniques to categorize legal documents by subject automatically. For this project, Lexum used its own language model. Automatic Classification enhances the search experience on the CanLII website, making it easier for users to contextualize individual results in long lists of search results.
This is also the perfect opportunity for Lexum to thank the Law Society of Saskatchewan for granting access to their Digest Database and the Law Society of Ontario for contributing data from the Ontario Reports. Both organizations provided the impetus for implementing the Automatic Classification feature on CanLII.
How does it work?
Automatic Classification analyzes the content and context of legal documents. Automatic Classification assigns appropriate subjects in the form of tags to each document. These subjects can include areas of law, legal topics, jurisdictions, court levels, and more. The subjects are integrated into the snippets accompanying search results alongside AI-powered keywords. They are also made available as a search filter under the Cases search tab.
The new language-based system has learned from historical law reports, such as the Canadian Supreme Court Reports and Federal Courts Reports, as well as many others, including the ones mentioned above.
Here is an example for the search “Unjust enrichment”:
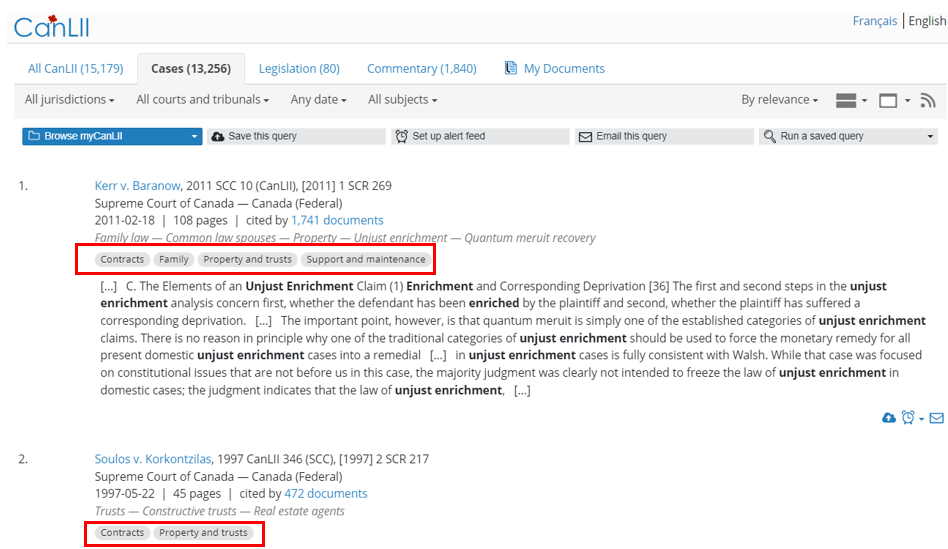
What is currently available and what is not?
At the present time, the classification model supports judicial decisions only. All Canadian English judicial decisions available on CanLII have been processed to include the subjects. However, administrative decisions have not been processed yet.
Also, even though the subjects have been translated into French, the Automatic Classification does not support French decisions just yet.
What is coming up?
Supporting French decisions is the current priority. Translating the tags is one thing, but adapting the language model itself requires further effort. We are hoping to be able to support French content shortly.
We also aim to make the tags clickable so that you will be able to select all content according to the corresponding subject.
Finally, our goal is to agglomerate subjects and keywords within a single paragraph, considering that the recently added subjects are, in reality, high-level keywords. This should make it even easier for users to quickly grasp the relevance of each individual search result in relation to their needs.




