



As a sequel to our recent post on Automatic Classification, we would like to introduce you to the science behind the show. The following article is adapted from the one presented by Benjamin Cérat, Software programmer at Lexum, as a workshop at ICAIL 2023. The 19th International Conference on Artificial Intelligence and Law took place from June 19th to 23rd, 2023, in Braga, Portugal.
Recent advances in natural language processing, such as large pre-trained transformer models, have opened a host of automation possibilities. The LexKey project is one of the initiatives pursued by Lexum to leverage these new tools to maximize access to legal information. The project first involved assembling a large dataset of annotated legal decisions from various sources. It allowed our team to train an abstractive generative model to produce useful and well-formatted keywords from legal documents.
This article presents the challenges involved and the steps we took to achieve this goal. It includes data cleaning to modify an existing model architecture for handling long legal documents. Finally, we’ll delve into the evaluation, both quantitative and qualitative, of the output.
Choosing the Model
The LexKey project started as a relatively basic proof of concept. The original prototype used a pre-trained model available on Huggingface, namely BigBirdPegasus (BBP), trained on the BIGPATENT dataset 1. The model was fine-tuned to generate keywords harvested from decisions found in the Ontario Reports, the Law Society of Saskatchewan Libraries databases and the Supreme Court of Canada Reports. The ability to handle fairly long documents was paramount, as Canadian decisions can vary from several sentences to novel length, averaging around six thousand words. One of the side benefits is to complement our own products, Decisia and Qweri, the latter having been specifically tailored for the online publishing of long legal documents.
The Challenges
While the preliminary results from BBP were promising, we outlined several issues regarding the resulting keywords.
First, pre-trained language models capable of handling long documents were unavailable for the French language. Also, the rare French legal models were either not accessible or not suited for Canadian common law.
Second, the selected model failed to generalize to decisions from jurisdictions outside the training scope. Inference on decisions from courts unseen in the training set was strongly biased toward topics typically included in law reports. As a result, it confused jurisdictions and generally did not meet the required standard.
Finally, the keyword format was quite inconsistent because the model learned from different reports, each having its own reporting style. Since the outputted keywords are meant to be assembled into search results lists, we sought more standardized outputs.
Adapting the Model vs Finding a New One
These preliminary results led us to open our views on other language models. A few other models were selected for experiments, all using an encoder-decoder architecture. Several elements drew us towards these models:
- the flexibility provided by separately designed encoder and decoder layers,
- the flexibility in the implementation of the pre-training objective (e.g. masked language modelling and denoising) and the attention architecture,
- the ease of managing multilingual models by simply using source and target language prompts.
As the LexKey project was nearing its completion, large decoder-based models such as OpenAI GPT were being released. They proved to perform well in text-generation tasks based on prompting schemes. The large-scale application of the most recent models (ChatGPT, GPT-4) to our corpus is left for future work.
All in all, most of the models we surveyed were performing very similarly on summarizing tasks, so the ease of adapting each model to our needs became the primary differentiator. Among these needs, the ability to handle long documents was vital. This skill is essential to our Decisia and Qweri document delivery solutions.
Sourcing
The LexKey project required a representative set of annotated decisions large enough to train a highly capable keyword generation model. The output of the model had to meet the quality expectations of our users. Instead of annotating by hand tens of thousands of decisions, we opted to gather case law databases that experts already tagged with keywords and categories.
Together with an experienced legal archivist, we set out to identify court decisions available on CanLII that featured keywords, often from Law Reports that had licensed content to CanLII. We also contacted third-party organizations offering such information to determine if they would be interested in collaborating. In the end, we gathered data from several Canadian sources.
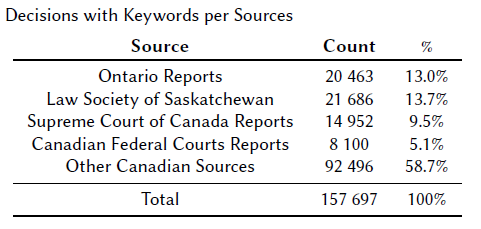
Preprocessing
In order to pre-train our language model, we used the raw text extracted from the HTML of the 3.1M decisions, 100k commentaries, and 85k statutes and regulations in French and English available on CanLII. We also gathered a large selection of English decisions tagged with appropriate keywords. Still, unfortunately, we could not get a suitable amount of equivalent French decisions in time for the initial release.
The documents were then shuffled and split into training (90%), validation (5%) and test (5%) sets. We also created a separate fine-tuning dataset containing the subset of decisions that were already tagged with keywords.
Normalization Between Sources
The available keywords for our training data came from multiple sources that rely on very different formats. To output standard results, we performed extensive normalization on the source data. Some sources of keywords appear to generate very terse tags, combining only two or three words, while others create very long descriptive sentences.
We introduced a keyword normalization step to our preprocessing to control the keyword format generated by our model (and avoid having it reproduce whichever source format the document resembles). Long keyword sequences were separated into a list of short keywords on one side, and descriptive sentences discussed case law and legislation on the other.
In the end, we had to abandon the idea of generating descriptive sentences because the models were prone to hallucinating facts or subtly inverting logical propositions found in the text. It created believable-sounding keywords that misrepresented the decision.
Removing these descriptive sentences from the learning sources did have some negative impact as they allowed more nuanced keywords referring to specific facts or arguments. It also meant that we had to remove some decisions that included only a single short keyword (e.g. a broad domain) followed by descriptive sentences. Once normalized, these broad domain keywords did not fit our preferred format.
Hand-Curated Test Set
To validate that the models generate keywords of good quality on data from out-of-sample sources, we also tasked editors to create a hand-labelled set of 500 documents distinct from the fine-tuning test set. The decisions included in this set were sampled from courts and tribunals not included in any of our sources of keywords. The central insight is that this process is time-consuming and not cost-effective, as treating each decision by a specialist takes about 15 minutes.
And since the keyword-gathering process was still underway, no documents in French could be included in this dataset. This meant excluding all decisions from Quebec for the time being.
Training the Models
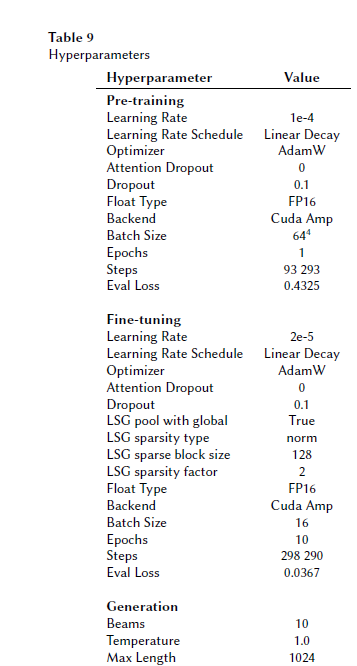
Starting from a pre-trained model checkpoint, we further pre-trained it with a denoising objective on our dataset of around 3.2M legal documents. This objective consisted of mask filling and fixing sentence permutation noise on chunks of the input documents.
Then, we converted the model’s full attention layers to LSG attention. The conversion from full to sparse attention makes the model less memory greedy. LSG uses, as the name suggests, a mix of Local, Sparse and Global attention along with a pooled representation of the rest of the input sequence. This allows the memory usage of attention computations to scale well to longer input lengths.
The Results
The new trained and fine-tuned models performed notably better than the first BigBirdPegasus, especially when given a larger learning input length. Quantitatively, the best-performing language on the ROUGE scoring was LexMBART-LSG-8k. However, these preliminary results are contradicted by the hand-curated test set, where the much smaller lexBART model produced the best scores. It could suggest that the model’s ability to generalize to documents from unseen jurisdictions will not necessarily improve as the sequence input length increases. It is also possible that longer input may dilute the relevant information in situations where the model is unsure.
Qualitatively, we must first emphasize that the model performed poorly on some subsets of court decisions. The ROUGE scoring index works well for quantity but less for quality. For instance, the models would generate predominantly random keywords for very short decisions. Two other fairly common problems identified during the qualitative analysis were missing topics and erroneous facts. So when we got rid of the subsets that were not efficient, the results would notably improve.
Discussion
Overall, in these experiments, lexBART scored well despite its much lower parameter count. If bilingual French and English support was not a requirement of the project down the line, its good performance would be a strong argument for picking the smaller model.
Both LSG models outperformed lexMBART, but all in all, the qualitative analysis showed only a limited difference in output quality between the lexMBART-LSG-4k and 8k models. Since the latter takes twice as long to run in both training and inference (and thus costs twice as much), we eventually decided to deploy the lexMBARTLSG- 4k model to production.
This choice necessitated adding an editorial override and a keyword blacklisting feature to the publishing pipeline. It also involved deploying the model to replace the legacy statistically-based keywords included in 1.3M English decisions available on CanLII. Processing those decisions took three days (using four workers, 16 threads and a batch size of 2 per GPU). The current intake of around 600 decisions per day is handled by a smaller machine on AWS running a single worker with a batch size of one.
Conclusions
The recent advances in language modelling and generation have given us the possibility to produce useful keywords to augment search results on the CanLII website. These efforts yielded an encoder-decoder language model nicknamed LexKey that was warm-started from MBART. We further pre-trained it on a large corpus of pre-tagged legal documents and fine-tuned to produce structured keywords similar to those produced by traditional legal publishers.
We believe that both this model and the large multi-source corpus specifically assembled for this project are essential building blocks for the future. They should allow us to further pursue natural language processing advances into useful automation that previously had to be performed manually by experts.
Despite the limitations we outlined, our custom-made keyword generator performs well, generating useful keywords for a large subset of our documents. Post-processing and a carefully selected keyword format have reduced undesirable behaviours.
The LexKey project was initiated in May 2021. In February 2023, the fine-tuned model was deployed live on CanLII on a large part of the English corpus. Although we cannot release the dataset because of our content providers’ policies, we will make our pre-training and fine-tuning scripts available along with the pre-trained model itself.
In the next development phase, we plan to source more French language decisions tagged with keywords to provide the same feature under both official languages (French documents were too scarce to be included in the fine-tuning dataset). We have also sourced 144K decisions from the Harvard Caselaw Access Project and 64K decisions from the Australian Federal Courts. We plan on using them to validate whether adding data from other common law countries can help improve our model. Finally, we are also testing the most recent large language models, such as GPT-4, for keyword generation.




