



Suite à notre récent article sur la classification automatique, nous aimerions vous présenter la science derrière le produit. Le présent article est adapté de celui présenté par Benjamin Cérat, programmeur logiciel chez Lexum, lors d’un atelier tenu dans le cadre de ICAIL 2023. La 19e Conférence internationale sur l’intelligence artificielle et le droit s’est déroulée du 19 au 23 juin 2023 à Braga, au Portugal.
Les progrès récents dans le traitement du langage naturel, tels que les grands modèles de transformeurs (ou modèle auto-attentif) pré-entraînés, ont ouvert une foule de possibilités d’automatisation. Le projet LexKey est l’une des initiatives de Lexum pour tirer parti de ces nouveaux outils afin de maximiser l’accès à l’information juridique. Le projet consistait d’abord à colliger un vaste ensemble de données juridiques annotées provenant de diverses sources. Notre équipe a pu créer un modèle génératif abstractif pour produire des mots-clés utiles et bien formatés à partir de documents juridiques.
Cet article présente les défis soulevés et les étapes que nous avons franchies pour atteindre cet objectif. Cela inclut le nettoyage des données, la modification d’ un modèle préexistant pour permettre la gestion de longs documents juridiques. Enfin, nous aborderons l’évaluation, à la fois quantitative et qualitative des résultats.
Choisir le modèle
Le projet LexKey a commencé en tant que preuve de concept relativement simple. Le prototype original utilisait un modèle préentraîné disponible sur Huggingface, à savoir BigBirdPegasus (BBP), entraîné sur l’ensemble de données BIGPATENT. Le modèle a été affiné pour générer des mots-clés récoltés à partir de décisions publiées dans les Recueils de Jurisprudence de l’Ontario, les bases de données des bibliothèques du Barreau de la Saskatchewan et les Recueil des arrêts de la Cour suprême du Canada. La capacité de traiter des documents assez longs était primordiale, car les décisions canadiennes peuvent varier de quelques phrases à la longueur d’un roman, avec une moyenne d’environ six mille mots. L’un des avantages secondaires est de compléter l’offre de nos propres produits, Decisia et Qweri, ce dernier ayant été spécialement conçu pour la publication en ligne de longs documents juridiques.
Les défis
Bien que les résultats préliminaires de BBP étaient prometteurs, nous avons identifié plusieurs problèmes concernant les mots-clés en résultant.
Premièrement, les modèles de langue pré-entraînés capables de gérer de longs documents n’étaient pas disponibles pour la langue française. De plus, les rares modèles juridiques français n’étaient pas accessibles ou ne convenaient pas à la common law canadienne.
Ensuite, le modèle sélectionné n’a pas réussi à s’adapter aux décisions des juridictions en dehors de l’échantillon d’entraînement. Ce problème était très apparent lors du traitement de décisions de tribunaux qui n’avait pas été vue lors de l’entraînement. Les mots-clés étaient fortement biaisés vers les sujets généralement inclus dans les recueils de jurisprudence. Le modèle confondait aussi les juridictions et plus généralement, ne répondait pas à nos critères d’évaluation.
Enfin, le format des mots-clés était assez incohérent car le modèle apprenait de différents recueils, chacun ayant son propre style d’écriture. Étant donné que les mots-clés générés sont destinés à être affichés dans des listes de résultats de recherche, nous avons cherché à obtenir des réponses plus homogènes.
Adapter le modèle vs en trouver un nouveau
Ces résultats préliminaires nous ont amenés à élargir nos horizons vers d’autres modèles de langue. Plusieurs autres modèles ont été sélectionnés pour expérimentations, tous utilisant une architecture encodeur-décodeur. Plusieurs paramètres nous ont attirés vers ces modèles :
- la flexibilité apportée par des couches encodeur et décodeur conçues séparément,
- la flexibilité dans la mise en œuvre de l’objectif de pré-entraînement (e.g. modélisation de langage masqué et débruitage) et de l’architecture de l’attention,
- la facilité à gérer des modèles multilingues en utilisant simplement des incitateurs de langue source et cible.
Alors que le projet LexKey arrivait à terme, de grands modèles basés sur des décodeurs tels que GPT3 d’OpenAI ont été rendus publics. Ils se sont avérés performants dans les tâches de génération de texte basées sur des schémas d’incitation. L’application à grande échelle des modèles les plus récents (ChatGPT, GPT-4) à notre corpus est réservée à des travaux futurs.
Dans l’ensemble, la plupart des modèles que nous avons étudiés offraient des résultats très similaires quant à la production de mots-clés, de sorte que la facilité d’adaptation de chaque modèle à nos besoins est devenue le principal facteur de différenciation. Parmi ces besoins, la capacité à traiter de longs documents était primordiale. Cette capacité est essentielle à nos solutions de gestion documentaire Decisia et Qweri.
Approvisionnement
Le projet LexKey nécessitait un ensemble représentatif de décisions annotées suffisamment grand pour entraîner un modèle de génération de mots clés hautement performant. Les réponses du modèle devaient répondre aux attentes de qualité de nos utilisateurs. Au lieu d’annoter à la main des dizaines de milliers de décisions, nous avons choisi de rassembler des bases de données de jurisprudence que les experts ont déjà étiquetées avec des mots-clés et des catégories.
En collaboration avec une archiviste juridique expérimentée, nous avons entrepris d’identifier les décisions judiciaires disponibles sur CanLII qui incluaient des mots-clés, souvent en provenance de Recueil de Jurisprudence qui avaient concédé du contenu sous licence à CanLII. Nous avons également contacté des organisations tierces offrant de telles informations afin de déterminer si elles seraient intéressées à collaborer. Pour finir, nous avons recueilli des données provenant de plusieurs sources canadiennes.
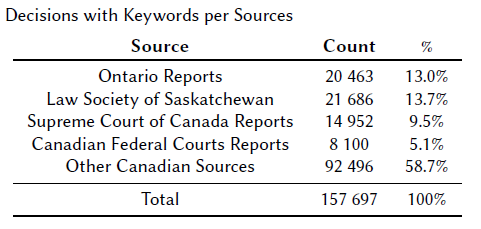
Prétraitement
Afin de pré-entraîner notre modèle de langue, nous avons utilisé le texte brut extrait du HTML des 3,1 millions de décisions, 100 000 commentaires et 85 000 lois et règlements en français et en anglais disponibles sur CanLII. Nous avons également rassemblé une large sélection de décisions en anglais étiquetées avec des mots-clés appropriés. Nous n’avons malheureusement pas pu obtenir un nombre suffisant de décisions rédigées en français à temps pour la publication initiale.
Les documents ont ensuite été mélangés et divisés en groupes d’entraînement (90%), de validation (5%) et de test (5%). Nous avons également créé un ensemble de données d’affinage à partir du sous-ensemble de décisions déjà étiquetées avec des mots-clés.
Normalisation entre les sources
Les mots-clés disponibles pour nos données d’entraînement provenaient de plusieurs sources qui s’appuient sur des formats très différents. Pour produire des résultats homogènes, nous avons effectué une normalisation approfondie sur les données-sources. Certaines sources de mots-clés semblent générer des rubriques très concises, de seulement deux ou trois mots, tandis que d’autres utilisent des phrases descriptives très longues.
Nous avons introduit une étape de normalisation des mots-clés dans notre prétraitement pour contrôler le format des mots-clés généré par notre modèle (et éviter qu’il ne reproduise le format du document source). Les longues séquences de mots-clés sont séparées en une liste de mots-clés courts, les phrases descriptives et finalement la jurisprudence et la législation discutée.
Finalement, nous avons dû abandonner l’idée de générer des phrases descriptives car les modèles étaient enclins à halluciner des faits ou à inverser subtilement des propositions logiques trouvées dans le texte. Les modèles créant des mots-clés crédibles qui déforment le contenu de la décision.
La suppression de ces phrases descriptives des sources d’apprentissage a eu un impact négatif car elles permettent des mots-clés plus nuancés faisant référence à des faits ou des arguments spécifiques. Cela signifiait également que nous devions supprimer certaines décisions qui ne comprenaient qu’un seul mot-clé court (par exemple, un domaine de droit) suivi de phrases descriptives. Une fois normalisés, ces mots-clés de domaine de droit ne correspondaient pas à notre format de préférence.
Ensemble de test traité manuellement
Pour valider que les modèles génèrent des mots-clés de bonne qualité sur des données provenant de sources hors-échantillon, nous avons également demandé à nos éditeurs de créer un ensemble de 500 documents étiquetés à la main distincts de l’ensemble de test de réglage affiné. Les décisions incluses dans cet ensemble proviennent de cours et de tribunaux et elles ne figurent dans aucune de nos sources de mots-clés. La conclusion principale est que ce processus prend du temps et est coûteux, car le traitement de chaque décision par un spécialiste prend environ 15 minutes.
Et puisque le processus de collecte des mots-clés était toujours en cours, aucun document en français n’a pu être inclus dans cet ensemble de données. Cela signifiait d’exclure toutes les décisions du Québec pour le moment.
Entraîner les modèles
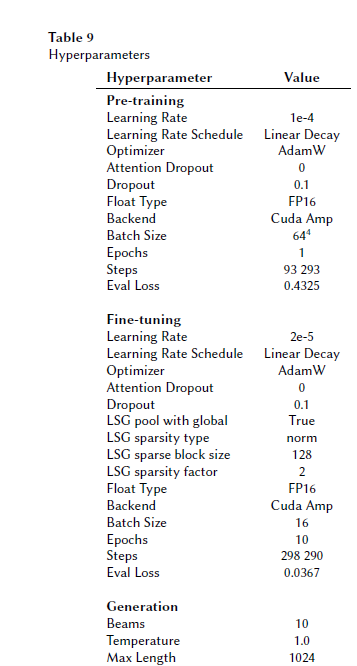
Nous avons poursuivi le pré-entrainement sur notre ensemble de données d’environ 3,2 millions de documents juridiques à partir d’un point de contrôle de modèle pré-entraîné en utilisant une tache de dé-bruitage comme objectif. Le tout consistait à remplir les données masquées et à corriger le bruit induit par des permutations des phrases sur des parties des documents à reconstituer.
Ensuite, nous avons converti les couches d’attention complète du modèle en attention LSG. La conversion de l’attention complète à l’attention clairsemée rend le modèle moins gourmand en mémoire. LSG utilise un mélange d’attention Locale, Sparse (Clairsemée) et Globale sur la séquence de texte en d’entrée. Cela permet de réduire l’utilisation de mémoire des calculs d’attention pour bien s’adapter à des longueurs d’entrée plus longues.
Les résultats
Les nouveaux modèles entraînés et affinés ont obtenu des résultats nettement meilleurs que le premier BigBirdPegasus, en particulier sur des textes plus long. Quantitativement, le modèle le plus performant sur le score ROUGE était LexMBART-LSG-8k. Cependant, ces résultats préliminaires sont contredits par l’ensemble de tests effectués manuellement, où le plus petit modèle lexBART a produit les meilleurs scores. Cela pourrait suggérer que la capacité du modèle à généraliser aux documents provenant de juridictions inconnues ne s’améliorera pas nécessairement à mesure que la longueur d’entrée de la séquence augmente. Il est également possible qu’un contexte plus long puisse diluer les informations pertinentes dans les situations où le modèle est incertain.
Sur le plan qualitatif, il faut d’abord souligner que le modèle a donné de mauvais résultats sur certains sous-ensembles de décisions judiciaires. La métrique de notation ROUGE fonctionne bien pour la quantité mais moins pour évaluer la qualité. Par exemple, nos modèles généraient principalement des mots-clés aléatoires pour des décisions très courtes. Deux autres problèmes assez courants relevés lors de l’analyse qualitative étaient les sujets manquants et les faits erronés. Ainsi, lorsque nous avons gardé les anciens mots-clés TF-IDF sur les sous-ensembles de décisions pour lesquels ça ne fonctionnait pas, les résultats se sont notablement améliorés.
Réflexion
Dans l’ensemble, lors de ces expériences, lexBART a obtenu de bons résultats malgré son nombre de paramètres beaucoup plus bas. Si le support bilingue français et anglais n’était pas une exigence du projet, sa bonne performance serait un argument de poids pour choisir le plus petit modèle.
Les modèles LSG ont tous deux surpassé lexMBART, mais dans l’ensemble, l’analyse qualitative n’a démontré qu’une différence limitée de qualité entre les modèles lexMBART-LSG-4k et 8k. Étant donné que ce dernier prend deux fois plus de temps pour l’entraînement et pour l’inférence (et coûte donc deux fois plus cher), nous avons finalement décidé de déployer le modèle lexMBARTLSG-4k en production.
Ce choix a nécessité l’ajout d’une capacité de remplacement par notre personnel éditorial et d’une fonctionnalité de liste noire de mots-clés dans le pipeline de publication. Cela impliquait également le déploiement du modèle pour remplacer les anciens mots-clés basés sur des statistiques et le traitement de 1,3 million de décisions en anglais disponibles sur CanLII. Le traitement de ces décisions a pris trois jours (en utilisant quatre travailleurs, 16 threads et une taille de lot de 2 par GPU). L’intégration quotidienne d’environ 600 décisions est gérée par une machine plus petite sur AWS exécutant un seul travailleur avec une taille de lot d’un.
Conclusions
Les avancées récentes en modélisation et génération de langue nous ont donné la possibilité de produire des mots-clés utiles pour améliorer les résultats de recherche sur le site Web de CanLII. Ces efforts ont abouti à créer un modèle de langue d’encodeur-décodeur surnommé LexKey qui a été lancé à chaud à partir de MBART. Nous l’avons en outre pré-entraîné sur un vaste corpus de documents juridiques et affiné pour produire des mots-clés structurés similaires à ceux produits par les éditeurs juridiques traditionnels.
Nous pensons que ce modèle et le vaste corpus multi-sources spécifiquement assemblé pour ce projet sont des éléments essentiels à développer dans le futur. Ils devraient nous permettre de poursuivre les progrès dans le traitement du langage naturel vers une automatisation efficace, alors que cela devait auparavant être traité manuellement par des experts.
Malgré les limitations que nous avons décrites, notre générateur de mots-clés sur mesure fonctionne bien, générant des mots-clés utiles pour une grande partie de nos documents. Le post-traitement et un format de mot-clé soigneusement sélectionné ont réduit les comportements indésirables.
Le projet LexKey a été lancé en mai 2021. En février 2023, le modèle affiné a été déployé en production sur CanLII pour une grande partie du corpus anglophone. Bien que nous ne puissions pas publier l’ensemble de nos données d’apprentissage en raison des politiques de nos fournisseurs de contenu, nous mettrons à disposition nos scripts de pré-entraînement et de réglage affiné avec le modèle pré-entraîné lui-même.
Dans la prochaine phase de développement, nous prévoyons de sourcer davantage de décisions en français étiquetées avec des mots-clés afin de fournir la même fonctionnalité dans les deux langues officielles (les documents en français étaient trop rares pour être inclus dans l’ensemble de données de réglage affiné). Nous avons également obtenu 144 000 décisions du Harvard Caselaw Access Project et 64 000 décisions des tribunaux fédéraux australiens. Nous prévoyons de les utiliser pour valider si l’ajout de données provenant d’autres pays de common law peut aider à améliorer notre modèle. Enfin, nous testons également les grands modèles de langue les plus récents, tels que GPT-4, pour la génération de mots clés.




